Modul 1 · KI verstehen
Was das Gehirn kann —
und warum das zählt
Predictive Processing. One-Shot Learning. Neuroplastizität. Bewusstsein. Warum das Gehirn noch immer das faszinierendste System ist, das wir kennen.
← → Navigieren · ESC zurück zur Übersicht

CC BY-SA 3.0 · N. Dilmen
Einstieg
Die falsche Frage
„Glaubst du, dass KI irgendwann so gut wird wie wir?"
Ich habe eine Weile gebraucht, um zu antworten. Nicht weil die Frage schwer ist. Sondern weil sie falsch ist.
„So gut wie wir" — was bedeutet das überhaupt?
Schach? Seit 1997. Mathematik-Olympiade? 2024, erstmals durch OpenAI. Proteine falten? AlphaFold, Chemie-Nobelpreis. Wenn das gemeint ist — es ist schon passiert.
Die eigentliche Frage
Aber was ist mit diesem „so gut wie wir"?
- Drei Beispiele sehen — sofort ein Konzept verstehen
- Eine halbvolle Kaffeetasse greifen und ihr Gewicht im Bruchteil einer Sekunde vorhersagen
- Mit drei Jahren die halbe Gehirnhälfte verlieren und trotzdem wieder laufen lernen
- Musik hören, die du nie erwartet hättest — und nicht weitergehen können
- Eine neue Sprache lernen, ohne dass man die alte vergisst
Das kann kein aktuelles KI-System
- One-Shot-Generalisierung auf neue Konzepte
- Sensomotorische Vorhersage in Echtzeit
- Plastizität nach dramatischem Verlust
- Kontinuierliches Lernen ohne zu vergessen
Teil 1 von 6
Das Gehirn als
Vorhersagemaschine
Predictive Processing — die vielleicht tiefgreifendste Idee der modernen Neurowissenschaft
Predictive Processing · Einstieg
Triest, 2024 — eine Geschichte über Vorhersagen
Ich saß in einer Gasse hinter dem Bahnhof, telefonierte halbherzig. Auf dem Weg, den ich kannte, auf Autopilot.
Dann, mitten in einem Satz — blieb ich stehen.
Aus einem Innenhof, den ich immer blind passiert hatte, kam Flamenco-Gitarre. Präzise, schnell. Ein alter Mann mit geschlossenen Augen.
Ich konnte nicht weitergehen. Das war kein bewusster Entschluss — mein Körper hatte einfach angehalten.
Erwartung: Stille
Realität: 🎸 Flamenco
→ Vorhersagefehler
Körper stoppt automatisch
Was das erklärt
Das Gehirn verarbeitet Abweichungen — nicht Bestätigungen. Alles was erwartet wird, kostet kaum Energie. Überraschungen kosten alles.
Predictive Processing
Das Gehirn schläft nie — es sagt voraus
Das Gehirn ist keine Maschine, die passiv auf Informationen wartet. Es tut ununterbrochen etwas Aktiveres:
Es baut ein Modell der nächsten Millisekunde.
- ☕ Wie schwer die Kaffeetasse ist, bevor du sie berührst
- 🚶 Wie die Treppe sich anfühlt, bevor dein Fuß aufsetzt
- 🎵 Den nächsten Ton in einem Lied, bevor er gespielt wird
- 📖 Das nächste Wort, bevor du es gelesen hast
Wenn sie nicht stimmt
Vorhersagefehler werden sofort eskaliert — Aufmerksamkeit, Bewusstsein. Das ist Überraschung.
Friston, K. (2010). Nature Reviews Neuroscience, 11(2).
Predictive Processing · Karl Friston
Das Free Energy Principle
Karl Friston formulierte 2005–2010 eine einheitliche Theorie des Gehirns:
Das Gehirn minimiert kontinuierlich freie Energie — also Überraschung bzw. Vorhersagefehler. Es tut das auf zwei Wegen:
Weg 1: Wahrnehmung
Interne Modelle an die Welt anpassen. Das Signal kommt von unten (Sinnesorgane), korrigiert die Vorhersage.
Weg 2: Handlung
Die Welt an die Vorhersagen anpassen. Active Inference: Handle so, dass deine Vorhersagen wahr werden.
Friston, K. (2005). Phil. Trans. R. Soc. B, 360(1456). · Friston, K. (2010). Nat. Rev. Neurosci.
Feedback-Verbindungen im visuellen Kortex sind anatomisch zahlreicher als Feedforward-Verbindungen — das Gehirn schickt mehr Information nach unten als nach oben.
Predictive Processing · Vergleich
Wo aktuelles Deep Learning strukturell anders ist
Biologisches Gehirn (PP)
- Bidirektional: Vorhersagen gehen nach unten, Fehler nach oben
- Generiert aktiv Erwartungen an jeden Input
- Lernt kontinuierlich, updatet Modell in Echtzeit
- Handelt, um Vorhersagen zu erfüllen (Active Inference)
- Placebo-Analgesie: Erwartung verändert Schmerzwahrnehmung physisch
Standard Deep Learning
- Feedforward-dominant: Input → Schichten → Output
- Kein generatives Vorhersagemodell über den Input
- Statische Gewichte nach dem Training
- Kein Active Inference-Mechanismus
- Attention hat gewisse Ähnlichkeit — aber kein iteratives PP
Das ist kein Kritik-Punkt, der KI schlechter macht. Es ist ein struktureller Unterschied der erklärt, warum bestimmte Fähigkeiten des Gehirns schwer zu replizieren sind.
Teil 2 von 6
One-Shot Learning —
ein Beispiel reicht
Wie das Gehirn aus einem einzigen Beispiel ein ganzes Konzept aufbaut — und warum das für KI so schwer ist
One-Shot Learning · Lake et al. 2015
Das Omniglot-Experiment
Brenden Lake und sein Team stellten 2015 eine einfache, aber vernichtende Frage an KI-Systeme:
Du siehst ein einziges Beispiel eines handgeschriebenen Zeichens. Kannst du es danach in neuen Schriften wiedererkennen?
Datensatz: Omniglot — 1.623 verschiedene handgeschriebene Zeichen aus 50 Alphabeten weltweit. Manchen davon hatten die Teilnehmer noch nie gesehen.
Lake, B. M., Salakhutdinov, R., & Tenenbaum, J. B. (2015). Science, 350(6266), 1332–1338.
Was getestet wird
- Ein einziges Beispielzeichen sehen
- Dasselbe Zeichen in 20 anderen Varianten erkennen
- Neue Instanzen des Konzepts erzeugen
- Verwandte Zeichen clustern
Warum das wichtig ist
Kinder lernen Konzepte aus wenigen Beispielen — nicht aus Millionen. Das ist der Normalfall biologischen Lernens.
One-Shot Learning · Ergebnisse
Mensch vs. Maschine — die Fehlerraten
| System | Fehlerrate (One-Shot) | Bewertung |
|---|---|---|
| Mensch | 4,5 % | Referenzwert — aus einem Beispiel generalisieren |
| Bayesian Program Learning (BPL) | 3,3 % | Besser als Mensch — modelliert Strichfolgen, Kausalität |
| Bester Deep-Siamese-ConvNet | 8,0 % | Doppelt so viele Fehler wie Mensch — trotz Millionen Trainingsbeispiele |
| Einfaches CNN | 13,5 % | ~3× schlechter als Mensch |
BPL schlägt den Menschen — aber nicht durch mehr Daten. Durch ein kausaleres Modell: Es lernt wie ein Zeichen gezeichnet wird, nicht nur wie es aussieht.
Dieser Unterschied — Erscheinung vs. Kausalstruktur — ist fundamental für das Verstehen. Das Gehirn lernt, wie Dinge entstehen.
Lake et al. (2015). Science, 350(6266). · Omniglot Challenge Progress Report (2019).
One-Shot Learning · Konsequenz
Was LLMs wirklich brauchen — und was das Gehirn nicht braucht
Was das Gehirn kann
- Neues Konzept aus 1–3 Beispielen ableiten
- Konzept auf neue Kontexte übertragen
- Neue Instanzen generieren (nicht nur klassifizieren)
- Verwandte Konzepte spontan clustern
Was aktuelle LLMs brauchen
- Hunderttausende Beispiele pro Konzept (im Trainingsdatensatz)
- Generalisierung bleibt oft oberflächlich
- Starke Tendenz zum Memorieren statt Verstehen
- Verteilung muss dem Training ähneln
Teil 3 von 6
Das Symbol Grounding
Problem
Warum LLMs nicht verstehen — und was „Verstehen" eigentlich bedeutet
Symbol Grounding · Searle 1980
Das Chinesische Zimmer
John Searle beschrieb 1980 ein Gedankenexperiment:
Eine Person sitzt in einem Zimmer. Durch einen Schlitz kommen chinesische Schriftzeichen herein. Die Person hat Regelbücher — exakt wie die Zeichen kombiniert werden. Sie gibt korrekte chinesische Antworten zurück. Von außen: perfektes Chinesisch. Von innen: kein Wort verstanden.
Syntax erzeugt keine Semantik. Korrekte Verarbeitung von Symbolen bedeutet nicht, dass man versteht, worum es geht.
Searle, J. R. (1980). Behavioral and Brain Sciences, 3(3), 417–424.
Die Analogie zum LLM
Ein Sprachmodell verarbeitet Token. Es hat gelernt, welche Token auf welche anderen folgen. Es gibt korrekte Antworten — ohne je einen Hund gesehen, einen Schmerz gespürt, eine Tasse gehoben zu haben.
Das Modell „weiß"
dass „Hund" und „bellt" zusammengehören. Aber das Wort ist nur in anderen Wörtern verankert — nicht in sensorisch-motorischer Erfahrung.
Symbol Grounding · Harnad 1990
Das Symbol Grounding Problem
Stevan Harnad formulierte 1990 das Problem präzise:
Wie können Symbole in einem formalen System intrinsische Bedeutung erhalten — nicht nur abgeleitete Bedeutung durch andere Symbole?
Ein Wörterbuch definiert „Hund" durch andere Wörter. Aber wenn du nie einen Hund gesehen, gehört, gerochen hast — was ist dann die Bedeutung?
Für Menschen: Symbole sind in sensorisch-motorischer Erfahrung verankert. Für LLMs: Symbole sind nur in anderen Symbolen verankert — ein geschlossenes System.
Harnad, S. (1990). Physica D, 42(1–3), 335–346.
Konkret: GPT und „Schmerz"
GPT kennt alle Kontexte in denen „Schmerz" vorkommt. Es kann darüber schreiben, Empathie imitieren, Ratschläge geben. Aber es hat nie Schmerz gespürt. Das Wort ist semantisch leer — nur statistisch reich.
Warum das praktisch wichtig ist
LLMs können bei abweichenden Formulierungen derselben Frage komplett andere Antworten geben — weil sie Oberflächen-Muster erkennen, nicht Bedeutung.
Symbol Grounding · Empirischer Beleg
MMLU-Kontamination: Memorierung statt Verstehen
Eine 2026er Studie variierte die Oberflächenform von MMLU-Fragen minimal — gleiche Bedeutung, andere Formulierung.
Ein System das versteht sollte dieselbe Frage unabhängig von der Formulierung lösen. −57% Genauigkeit bei Oberflächenvariation ist ein direkter Beleg für Memorierung statt Reasoning.
Reasoning-Modelle (o3-mini, DeepSeek-R1) sind resistenter — aber auch hier deutlicher Leistungsabfall. Das Problem ist strukturell, nicht modellspezifisch.
arXiv 2603.16197 (2026). „Are Large Language Models Truly Smarter Than Humans?"
Teil 4 von 6
Neuroplastizität —
das Gehirn formt sich selbst
Warum das Gehirn nach massivem Verlust funktioniert — und warum neuronale Netze das nicht können
Neuroplastizität · Extremfall
Cameron Mott — das radikalste Beispiel
Cameron Mott wurde mit 3 Jahren mit Rasmussen-Enzephalitis diagnostiziert — einer seltenen Erkrankung, bei der eine Gehirnhälfte fortschreitend zerstört wird.
Die Lösung: Hemisphärektomie — die komplette rechte Gehirnhälfte wurde entfernt.
Vier Wochen nach der OP: sie läuft aus der Klinik. Heute Schule, normale kognitive Entwicklung.
Ihre verbleibende linke Hälfte übernahm die Funktionen beider Hälften — komplett reorganisiert.
→ Hälfte des Gehirns entfernt
→ 4 Wochen später: läuft raus
→ Schule, normale Entwicklung
Das Gehirn hat sich neu gebaut.
🤖 Ein neuronales Netz?
Entferne 50% der Gewichte — es kollabiert. Keine Reorganisation. Statische Struktur.
Neuroplastizität · Mechanismus
Wie Lernen im Gehirn physisch passiert — LTP
Long-Term Potentiation (LTP) ist der zelluläre Mechanismus des Gedächtnisses, erstmals beschrieben von Bliss & Lømo 1973:
Hebbsche Regel: „Cells that fire together, wire together." — gleichzeitige Aktivität stärkt die Verbindung.
Bliss, T. V. & Lømo, T. (1973). Journal of Physiology, 232(2), 331–356.
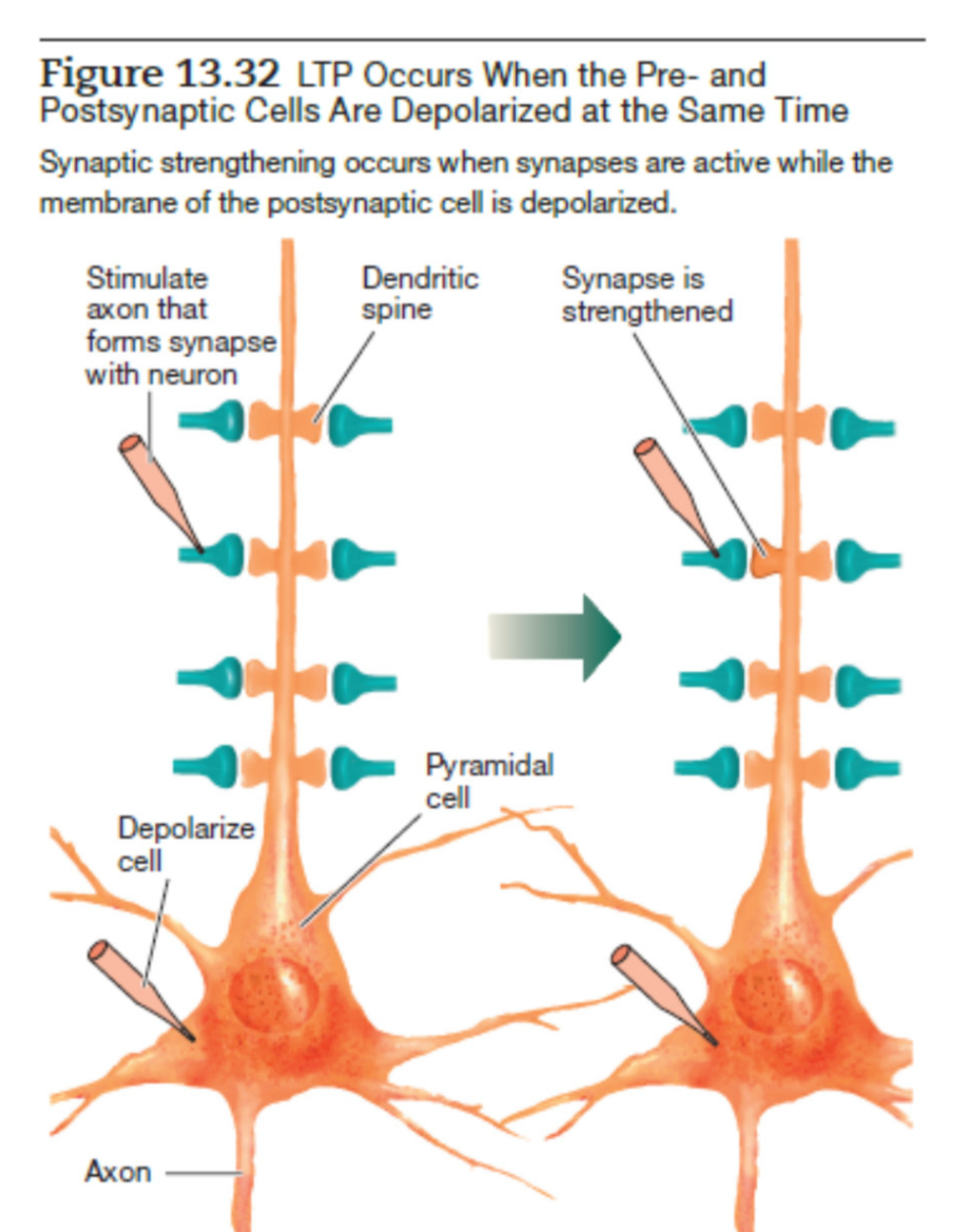
Aus: Brain Online Vault · Neuroscience textbook Fig. 13.32
Unterschied zum KI-Training
Backpropagation ändert Gewichte offline, in Batches. LTP passiert in Echtzeit, kontinuierlich, lokal — ohne globales Signal, das durch das ganze Netz propagiert.
Neuroplastizität · KI-Grenze
Catastrophic Forgetting — das größte Lernproblem der KI
McCloskey & Cohen beschrieben 1989 das grundlegende Problem sequenziellen Lernens in Neuronalen Netzen:
Wenn ein Netz auf Aufgabe B trainiert wird, zerstört es dabei die Repräsentationen für Aufgabe A. Das alte Wissen wird überschrieben.
Das Gehirn hat dieses Problem nicht. Warum?
Complementary Learning Systems (McClelland et al. 1995): Hippocampus speichert neue Episoden schnell, Kortex integriert sie langsam — ohne das Alte zu überschreiben.
McCloskey & Cohen (1989). Psychology of Learning and Motivation, 24. · McClelland et al. (1995).
KI: Fine-Tuning-Problem
- GPT-4 auf neue Daten fine-tunen → alte Fähigkeiten degradieren
- Keine stabile Langzeitrepräsentation
- Lösung bisher: Daten immer gleichzeitig halten (teuer)
Gehirn: Kein Vergessen durch Lernen
- Du lernst Fahrradfahren — ohne Laufen zu vergessen
- Du lernst Französisch — ohne Deutsch zu vergessen
- Neue Episoden werden integriert, nicht überschrieben
Teil 5 von 6
20 Watt —
das effizienteste Rechensystem
Warum der Energievergleich zwischen Gehirn und KI so verblüffend ist
Energie · Das Gehirn
Das Gehirn läuft mit einem USB-C-Ladegerät
Raichle & Gusnard, PNAS 2002
das ist genau so viel wie dein Gehirn dauerhaft braucht.
Das komplexeste bekannte System im Universum.

CC BY-SA 4.0 · PiDatacenters
GPT-4 Training = 3.600 Menschenleben
50 GWh Trainingsenergie ÷ (20 W × 80 Jahre) = ~3.600 Gehirne ein Leben lang. Einmaliger Trainingsvorgang. Keine Generalität.
Energie · Trainingskosten
GPT-4 Training vs. ein menschliches Leben
Das ist keine Kritik an KI. Es ist eine Einladung zu fragen: Wie schafft das Gehirn so viel mit so wenig? Die Antwort liegt in der Architektur — spiking, asynchron, lokal, bidirektional.
Neuromorphic Computing
IBM TrueNorth (2014): 1 Mio. Neuronen, 65 mW — ~400 Mrd. Synapsenoperationen/s/Watt. Intel Loihi 2 (Hala Point): geschätzt 1.000× effizienter als GPUs für neuronale Netzinferenz.
Patterson et al. (2021). arXiv 2104.10350. · Merolla et al. (2014). Science.
Teil 6 von 6
Bewusstsein, DishBrain
und die Frage nach AGI
Was Neuronen in einer Petrischale uns über Lernen lehren — und was AGI eigentlich bedeuten würde
Bewusstsein · DishBrain
800.000 Neuronen lernen Pong — in 5 Minuten
2022 beschrieb Brett Kagan ein Experiment, das die Grenzen zwischen biologisch und künstlich verwischte:
- 800.000 menschliche und Maus-Neuronen in einer Petrischale mit Elektroden
- Ballposition wurde als Signalmuster kodiert (links/rechts, Frequenz = Abstand)
- Treffer = geordnete Signalaktivität, Fehler = chaotisches Weißrauschen
- Die Neuronen optimierten ihr Verhalten — in unter 5 Minuten
Menschliche Neuronen erreichten dabei ein höheres Spielniveau als Maus-Neuronen.
Kagan, B. J. et al. (2022). Neuron, 110(23), 3952–3969.
Was das bedeutet
Biologische Neuronen ohne Körper, ohne Ziel, ohne Training im herkömmlichen Sinne — lernen Feedback zu optimieren. Das ist emergentes Lernen auf Zellebene.
Was das nicht bedeutet
Kein Bewusstsein, kein Erleben, kein Verstehen von Pong. Aber es zeigt: Lernen ist ein biologisch fundamentales Prinzip — nicht eine Eigenschaft von Architektur.
Bewusstsein · Theorien
Was ist Bewusstsein? — Zwei große Theorien
Global Workspace Theory (GWT)
Baars (1988): Bewusstsein entsteht, wenn Informationen in einem „globalen Arbeitsraum" des Gehirns weit verteilt werden — für alle Hirnregionen zugänglich gemacht.
Bewusstsein = globaler Broadcast. Lokal verarbeitete Information wird „öffentlich" im Gehirn.
Integrated Information Theory (IIT)
Tononi (2004, 2008): Bewusstsein = integrierte Information (Φ). Jedes System mit hohem Φ hat Bewusstsein — unabhängig davon, ob es biologisch ist.
Konsequenz: Manche Tiere, vielleicht Pflanzen — und möglicherweise bestimmte KI-Architekturen — hätten Bewusstsein.
Melloni et al. (Nature, 2025): Erste adversarielle Studie GWT vs. IIT — fMRI, MEG, intrakraniales EEG. Ergebnis: Kein klarer Gewinner. Das Problem des Bewusstseins ist empirisch noch offen.
Melloni et al. (2025). Nature. · Baars (1988). · Tononi (2004, 2008).
AGI · Definition
AGI — was würde das wirklich bedeuten?
„Wenn du zehn KI-Experten fragst, was AGI ist, bekommst du 20 verschiedene Antworten."
Die Definitionen reichen von „besseres Verständnis als jeder Mensch in jedem Themenfeld" bis zu „agiert in der Welt wie ein Mensch". Je nach Definition liegt AGI näher oder ferner.
Meine Definition: AGI braucht kontinuierliches Lernen — die Fähigkeit, neue Aufgaben ohne Katastrophisches Vergessen zu integrieren, während man sich selbstständig in einer physischen Welt bewegt.
R2D2 aus Star Wars als intuitives Bild: erkennt Zusammenhänge, bewegt sich selbstständig, scheint zu verstehen — nicht nur zu berechnen.
Was heutige Systeme fehlt
- Kontinuierliches Lernen ohne Vergessen
- Sensomotorische Verankerung in der Welt
- One-Shot-Generalisierung auf neue Domänen
- Kausalverstehen statt Mustererkennung
- Echte Ziele und Intentionen
Das bedeutet nicht, dass AGI prinzipiell unmöglich ist. Aber „Wir haben AGI bis 2030" nach welchen Kriterien?
Synthese
Die zentrale These dieses Moduls
Die wahre Gefahr liegt nicht darin, dass KI zu klug wird — sondern dass wir uns täuschen lassen und Verstehen mit Rechenleistung verwechseln.
Was KI kann
- Schach, Go, Mathematik-Olympiade
- Milliarden Parameter optimieren
- Sprachlich überzeugend klingen
- Proteine falten, Diagnosen unterstützen
Was KI strukturell nicht kann
- Aus einem Beispiel ein Konzept aufbauen
- Symbole in Erfahrung verankern
- Kontinuierlich ohne zu vergessen lernen
- Sich selbst nach massivem Verlust reorganisieren
KI ist mächtig. Aber wer die Unterschiede versteht, nutzt KI klüger — und überschätzt sie nicht.
Zusammenfassung · Modul 1
Was du jetzt weißt
Predictive Processing
- Gehirn sagt voraus, nicht nur reagiert
- Vorhersagefehler → Aufmerksamkeit
- Bidirektional: KI ist feedforward-dominant
One-Shot Learning
- Omniglot: 1 Beispiel reicht dem Menschen
- CNNs brauchen Zehntausende
- BPL schlägt Mensch durch Kausalmodell
Symbol Grounding
- Chinesisches Zimmer: Syntax ≠ Semantik
- LLMs: Symbole in Symbolen verankert
- −57% Genauigkeit bei Formulierungsvarianten
Neuroplastizität
- Cameron Mott: halbe Gehirnhälfte entfernt
- LTP: zellulärer Mechanismus des Lernens
- Catastrophic Forgetting: KI-Kernproblem
Energie
- Gehirn: 20 Watt — USB-C-Ladegerät
- GPT-4-Training: 3.600 Gehirn-Leben
- Neuromorphic: IBM TrueNorth, Loihi
Bewusstsein & AGI
- DishBrain: Neuronen lernen Pong
- GWT vs. IIT — noch kein Gewinner
- AGI braucht kontinuierliches Lernen
Modul 1 abgeschlossen
Modul 2: Wie KI funktioniert
Jetzt wo du weißt, was dem Gehirn einzigartig ist — wie versucht KI das nachzubauen? Neuronale Netze, Transformer, Sprachmodelle von innen.