Modul 2 · KI verstehen
Wie KI
wirklich
funktioniert
Vom einzelnen Neuron bis zum Sprachmodell — technisch, aber zugänglich.
Pfeiltasten oder Buttons zum Navigieren · ESC für Kursübersicht
Eine Frage
ChatGPT denkt nicht.
Es rät.
Genauer gesagt: Es berechnet, welches Wort als nächstes am wahrscheinlichsten kommt — Milliarden Mal, in Millisekunden. Das klingt simpel. Aber wie entsteht daraus etwas, das Gedichte schreibt, Code debuggt und philosophische Fragen beantwortet?
wenn man die Antwort kennt.
Teil 1 von 5
Die Grundbausteine
Von der biologischen Nervenzelle zum künstlichen neuronalen Netz — wie das Vorbild in Mathematik übersetzt wurde.
Einstieg
Was meinen wir überhaupt mit „KI"?
Was KI ist
- Software die aus Daten lernt
- Muster erkennt — auch in Sprache
- Vorhersagen macht (nicht "denkt")
Was KI nicht ist
- Kein allwissender Orakel
- Kein Bewusstsein, kein Verständnis
- Kein Blick in die Zukunft
KI ist ein sehr guter Mustererkenner und Musterfortsetzer — aufgebaut aus Millionen von Parametern, trainiert auf riesigen Datensätzen.
Grundlagen
Das Vorbild: das biologische Neuron 🧬
Ein Neuron empfängt Signale über Dendriten, summiert sie, und feuert einen Output über das Axon — aber nur wenn eine Schwelle überschritten wird.
86 Milliarden solcher Neuronen im Gehirn — je bis zu 10.000 Verbindungen
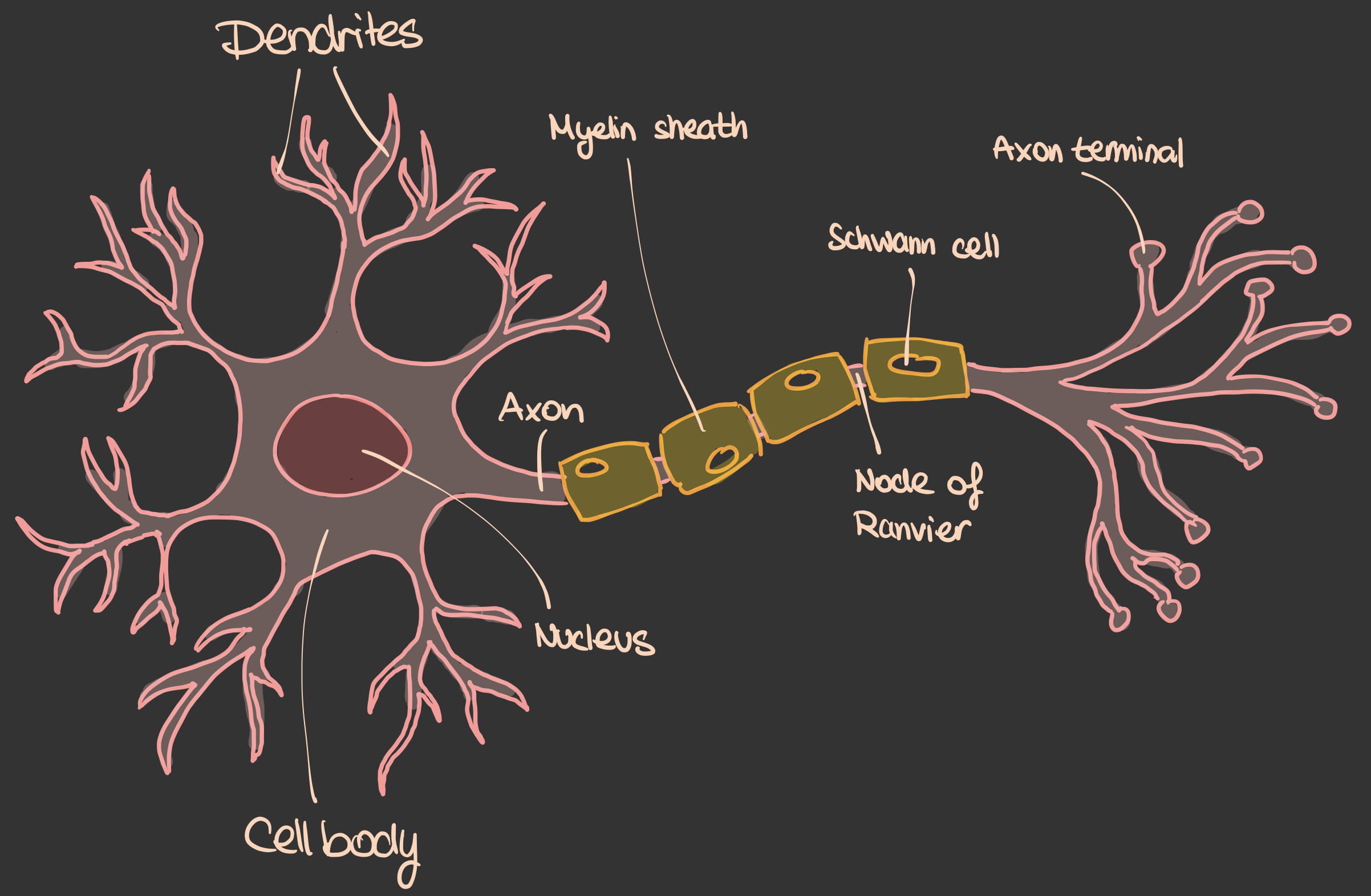
das ist was beim Lernen
angepasst wird. Sonst nichts.
Grundlagen
Das künstliche Neuron
Jeder Input x bekommt ein Gewicht w. Das Neuron summiert alle gewichteten Inputs, addiert einen Bias, und schickt das Ergebnis durch eine Aktivierungsfunktion.
Warum Gewichte?
Gewichte bestimmen wie wichtig ein Input ist. Das Lernen = die Gewichte so anpassen, dass die Ausgabe stimmt.
Warum Aktivierung?
Ohne Aktivierungsfunktion wäre das Netz nur eine lineare Gleichung — egal wie viele Schichten. Aktivierungen ermöglichen Nichtlinearität.
Grundlagen
Viele Neuronen = ein Netzwerk
Was jede Schicht lernt
- Frühe Schichten: einfache Muster (Kanten, Töne, Zeichen)
- Mittlere Schichten: Kombinationen (Formen, Wörter)
- Tiefe Schichten: abstrakte Konzepte ("Katze", "Ironie")
Kein Mensch hat diese Muster programmiert — das Netz findet sie selbst durch Training auf Daten.
Training
Wie Lernen tatsächlich passiert
- Vorhersage: Netz gibt einen Output
- Fehler messen: Wie falsch war die Vorhersage? (Loss-Funktion)
- Rückwärts: Welches Gewicht ist schuld? (Backpropagation)
- Korrigieren: Gewichte minimal anpassen (Gradient Descent)
- Wiederholen: Millionen Mal, mit Milliarden Beispielen
Gradient Descent
Stelle dir einen Ball der einen Hügel hinunterrollt — immer in Richtung des steilsten Gefälles. Gradient Descent rollt die Gewichte in Richtung des kleinsten Fehlers.
GPT-4 wurde auf ~13 Billionen Tokens trainiert. Jedes Token = ein Backpropagation-Schritt.
Teil 2 von 5
Wie KI lernt
Training, Fehler, Gradient Descent — wie ein Netz durch Milliarden von Korrekturen immer besser wird.
Schlüsselkonzept
Gradient Descent — der Ball rollt bergab
Der Fehler sinkt mit jedem Trainingsschritt
Das Netz macht eine Vorhersage → misst seinen Fehler → passt alle Gewichte minimal an, um den Fehler zu verringern.
GPT-4 wurde auf ~13 Billionen Tokens trainiert. Das bedeutet: 13 Billionen solcher Korrekturen — jede winzig, zusammen: ein Sprachmodell.
„Berlin ist die Hauptstadt von Deutschland."
Es hat es aus Milliarden Beispielen selbst abgeleitet.
Deep Learning
Warum „Deep" Learning?
Flaches Netz (1–2 Layer)
Kann einfache Muster lernen. Scheitert an komplexen Zusammenhängen. Braucht riesige Breite.
Tiefes Netz (viele Layer)
Lernt Hierarchien von Merkmalen. Jede Schicht baut auf der vorherigen auf. Effizienter bei gleicher Leistung.
Der Durchbruch
2012: AlexNet gewinnt ImageNet mit 8 Schichten. Davor undenkbar. Tiefe + Daten + GPU = Revolution.
Deep Learning ist nicht neu (Ideen aus den 80ern) — aber erst mit genug Daten und Rechenleistung entfaltete es seine Stärke.
Teil 3 von 5
KI sieht
Wie Computer lernen, Bilder zu verstehen — und warum die Lösung aussieht wie der visuelle Kortex.
Spezialarchitekturen
Convolutional Networks — wie ein Gehirn Bilder sieht 👁️
Standard-Netze behandeln jeden Pixel unabhängig. CNNs schauen auf kleine Ausschnitte und suchen nach lokalen Mustern — egal wo im Bild.
Was CNNs können
- 🖼️ Bilder klassifizieren (Katze / Hund)
- 📍 Objekte erkennen und lokalisieren
- 🎵 Muster in Audio und Text
Derselbe 3×3-Kernel gleitet über das gesamte Bild. Egal ob die Kante links oben oder rechts unten ist — erkannt wird sie trotzdem.
Teil 4 von 5
KI liest
Transformer, Attention, Token-Vorhersage — wie Sprachmodelle Sprache verarbeiten und wie ChatGPT aus GPT wird.
Das Problem
Das Problem mit Sprache: Reihenfolge und Abhängigkeit
Ältere Ansätze (RNNs) verarbeiteten Text sequenziell — Wort für Wort. Problem: Bei langen Texten vergessen sie den Anfang.
„Der Mann, der gestern mit meiner Schwester, die übrigens seit Jahren in Berlin lebt, gesprochen hat, war müde."
Das Netz muss wissen: „war" bezieht sich auf „Mann" — nicht auf „Schwester" oder „Berlin".
Das Kernproblem
- Langfristige Abhängigkeiten
- Kein paralleles Verarbeiten möglich
- Kontext geht bei langen Texten verloren
Die Lösung (1 Folie später)
Statt sequenziell — alle Wörter gleichzeitig betrachten und gezielt "aufmerksam" sein.
Transformer
Attention — die Schlüsselidee 🎯
Für jedes Wort: Auf welche anderen Wörter soll ich achten? Das Ergebnis ist ein Gewicht für jede Wort-Wort-Beziehung.
„war" → schaut hauptsächlich auf „Mann" (0.72)
Query, Key, Value
Jedes Wort erzeugt drei Vektoren:
Query — „Wonach suche ich?"
Key — „Was biete ich an?"
Value — „Was ist mein Inhalt?"
Vaswani et al., 2017 (Google)
8 Seiten. Eines der meistzitierten Papers der KI-Geschichte.
Transformer
Transformer-Architektur — der Bauplan
1. Tokenisierung
Text wird in Tokens zerlegt (Wörter, Wortteile). Jeder Token bekommt einen Zahlenvektor (Embedding).
2. Self-Attention
Jeder Token schaut auf alle anderen — mit mehreren parallelen "Köpfen" (Multi-Head Attention). Kontext entsteht.
3. Feed-Forward + Norm
Ergebnis durch ein kleines neuronales Netz, dann normalisiert. Das Ganze wiederholt sich N-mal (GPT-4: ~96 Schichten).
Das Entscheidende: Alles passiert parallel, nicht sequenziell. Das macht Transformer schnell trainierbar — und skalierbar auf Millionen von GPU-Stunden.
Sprachmodelle
Wie erzeugt ein Sprachmodell Text?
Ein Sprachmodell wurde trainiert eine einzige Aufgabe zu lösen:
Sage vorher: Was kommt als nächstes?
Input: „Die Hauptstadt von Deutschland ist"
Output-Wahrscheinlichkeiten: „Berlin" 94%, „München" 3%, „Hamburg" 2%, ...
Das Modell wählt ein Token, fügt es an, und wiederholt — Token für Token, bis der Text fertig ist.
Temperature
Steuert wie "kreativ" das Sampling ist. Niedrig = deterministisch. Hoch = überraschend (manchmal zu überraschend).
Kein Verständnis — nur Statistik?
Umstrittene Frage. Das Modell hat keine Absichten — aber die Muster die es gelernt hat, sind nicht trivial.
Von GPT zu ChatGPT
RLHF — wie KI lernt, hilfreich zu sein
Ein Sprachmodell direkt nach dem Training ist kein guter Assistent. Es setzt Muster fort — auch unangenehme. Ein zweiter Trainingsschritt ändert das:
Ouyang et al. (2022) „Training language models to follow instructions", OpenAI
Buchstäblich: Menschen klicken „Antwort A ist besser als B" — Tausende Mal. Das KI-System lernt aus diesen Signalen.
Was das erklärt
Warum Claude höflich ist, Grenzen hat und keine Hassrede produziert — nicht weil es das "versteht", sondern weil dieses Verhalten beim Training belohnt wurde.
Teil 5 von 5
Skalierung und Grenzen
Was passiert wenn Modelle wachsen — und wo auch die größten Systeme an strukturelle Wände stoßen.
Warum immer größer?
Skalierungsgesetze
Mehr Parameter + mehr Daten + mehr Rechenleistung = vorhersagbar bessere Modelle. Das ist empirisch robust — und überraschend gleichmäßig.
GPT-2 (2019): 1.5B Parameter
GPT-3 (2020): 175B Parameter
GPT-4 (2023): ~1.8T Parameter (geschätzt)
Claude 3 Opus: ähnliche Größenordnung
Emergenz
Ab bestimmten Größen tauchen Fähigkeiten auf die man nicht explizit trainiert hat: Mehrsprachigkeit, Analogieschlüsse, einfaches Schlussfolgern.
Niemand hat verstanden warum genau bestimmte Fähigkeiten bei bestimmten Schwellen entstehen. Das ist aktive Forschungsfrage.
Grenzen
Was KI nicht kann — und warum das wichtig ist
- Kein echtes Verständnis: Kein Modell "weiß" was es sagt — es setzt Muster fort
- Kein Gedächtnis: Jeder Kontext beginnt neu (ohne externe Systeme)
- Halluzinationen: Konfidente Falschaussagen sind strukturell möglich
- Kein Körper, kein Erleben: Keine Sinneswahrnehmung, kein "Fühlen" im Sinne von Qualia
- Kein Weltwissen in Echtzeit: Trainingsdaten haben ein Cut-off-Datum
Diese Grenzen sind kein Bug — sie sind aus der Architektur ableitbar. Wer KI nutzt sollte wissen wo das System strukturell schwach ist.
Praktische Konsequenz
KI als Werkzeug, nicht als Autorität. Outputs prüfen. Kritisch bleiben. Das ist keine Vorsicht — das ist technisches Verständnis.
So what?
Warum ist das Verstehen wichtig?
Bessere Nutzung
Wer versteht wie ein Sprachmodell „denkt", schreibt bessere Prompts und erkennt wann das Modell halluziniert.
Bessere Einschätzung
Hype von Substanz trennen. Medienberichte über „KI die fühlt" richtig einordnen. Nicht überängstlich, nicht blauäugig.
Bessere Entscheidungen
Als Gesellschaft, als Organisation, als Individuum: Wer versteht was KI kann und was nicht, entscheidet informierter.
KI-Kompetenz ist keine Nischen-Fähigkeit mehr. Es ist das neue Grundwissen — wie Lesen und Schreiben für das digitale Zeitalter.
Modul 2 abgeschlossen
Wie KI funktioniert
- Neuronale Netze: Gewichte, Schichten, Aktivierung
- Training: Backpropagation, Gradient Descent
- Transformer: Attention, Token-Vorhersage
- Grenzen: Halluzination, kein Verständnis, kein Gedächtnis